Self-Managed Machine Learning Workshop
This workshop has been moved to https://catalog.workshops.aws/ml-on-aws-parallelcluster and will no longer be updated. Please go there.
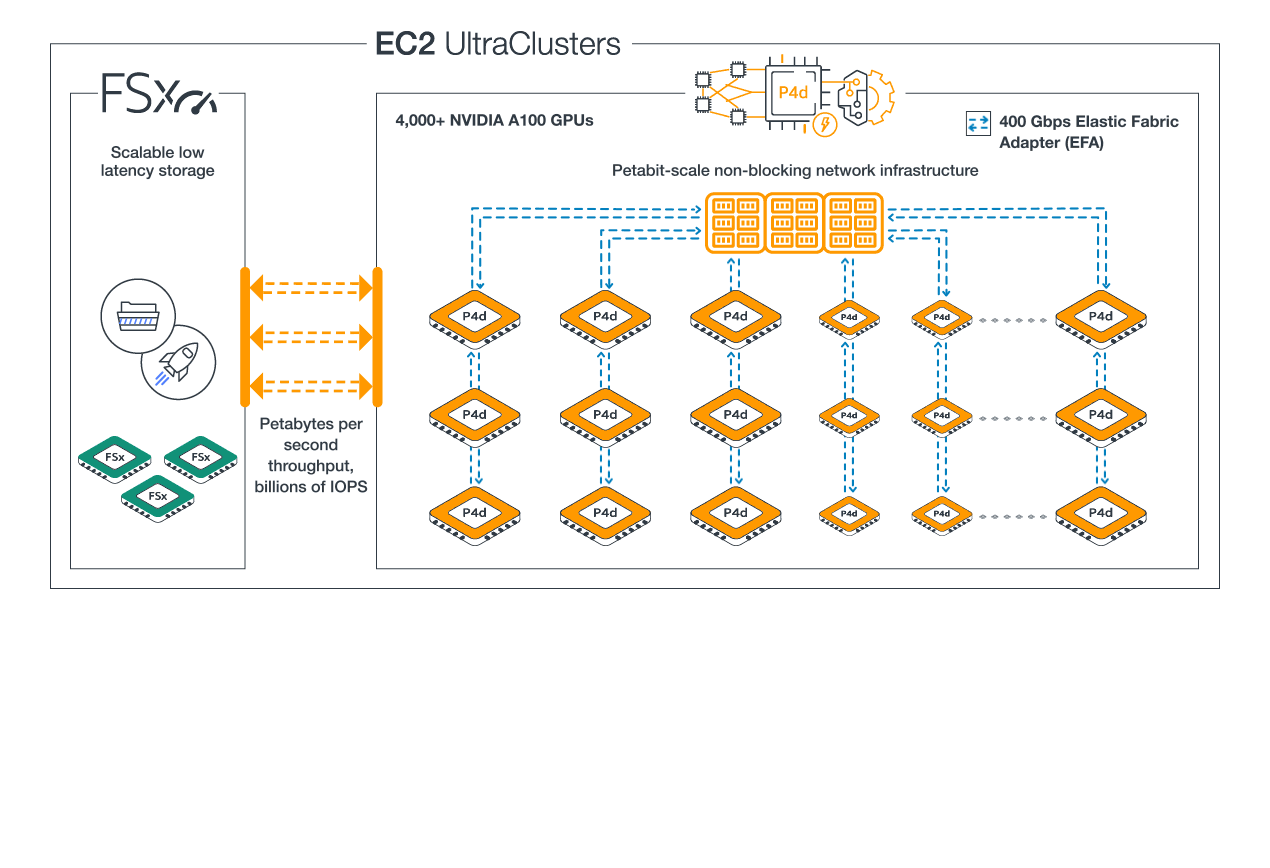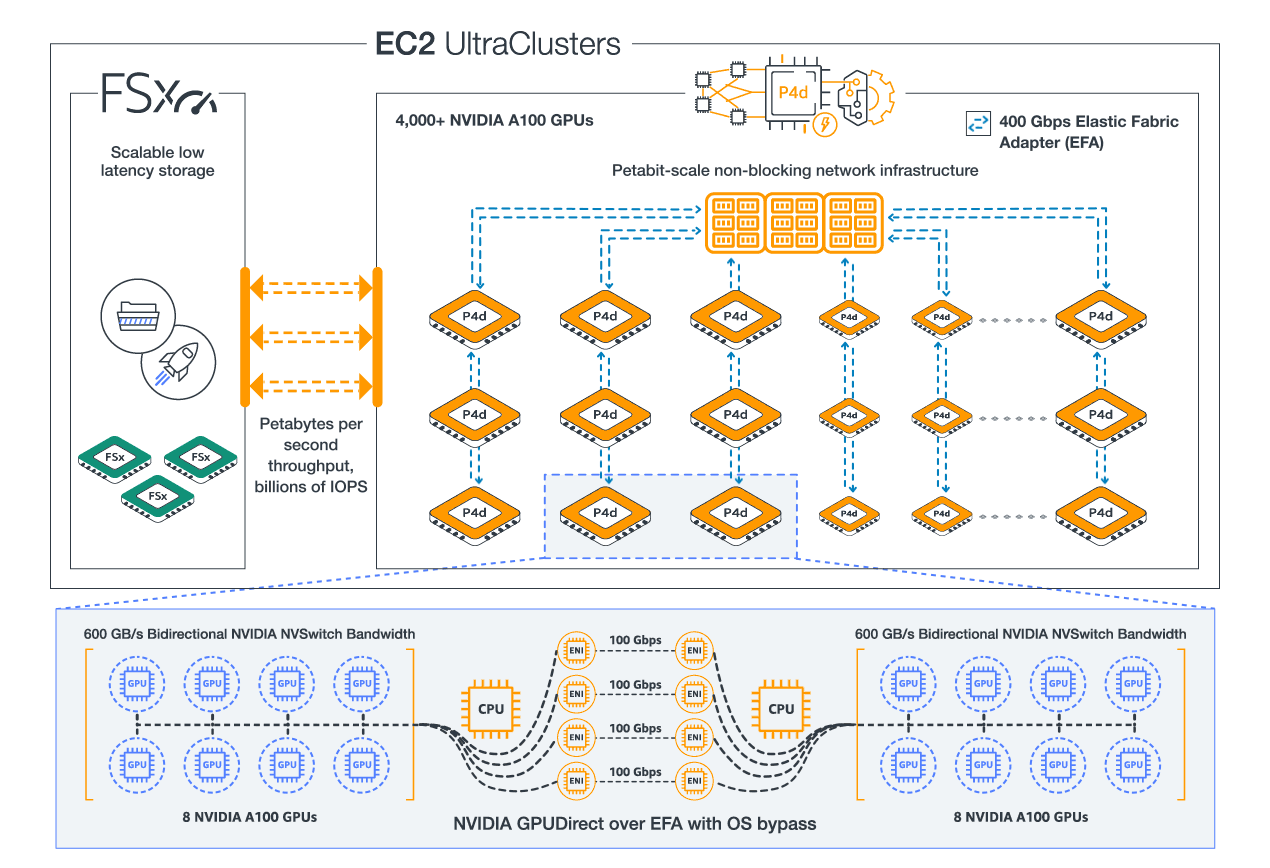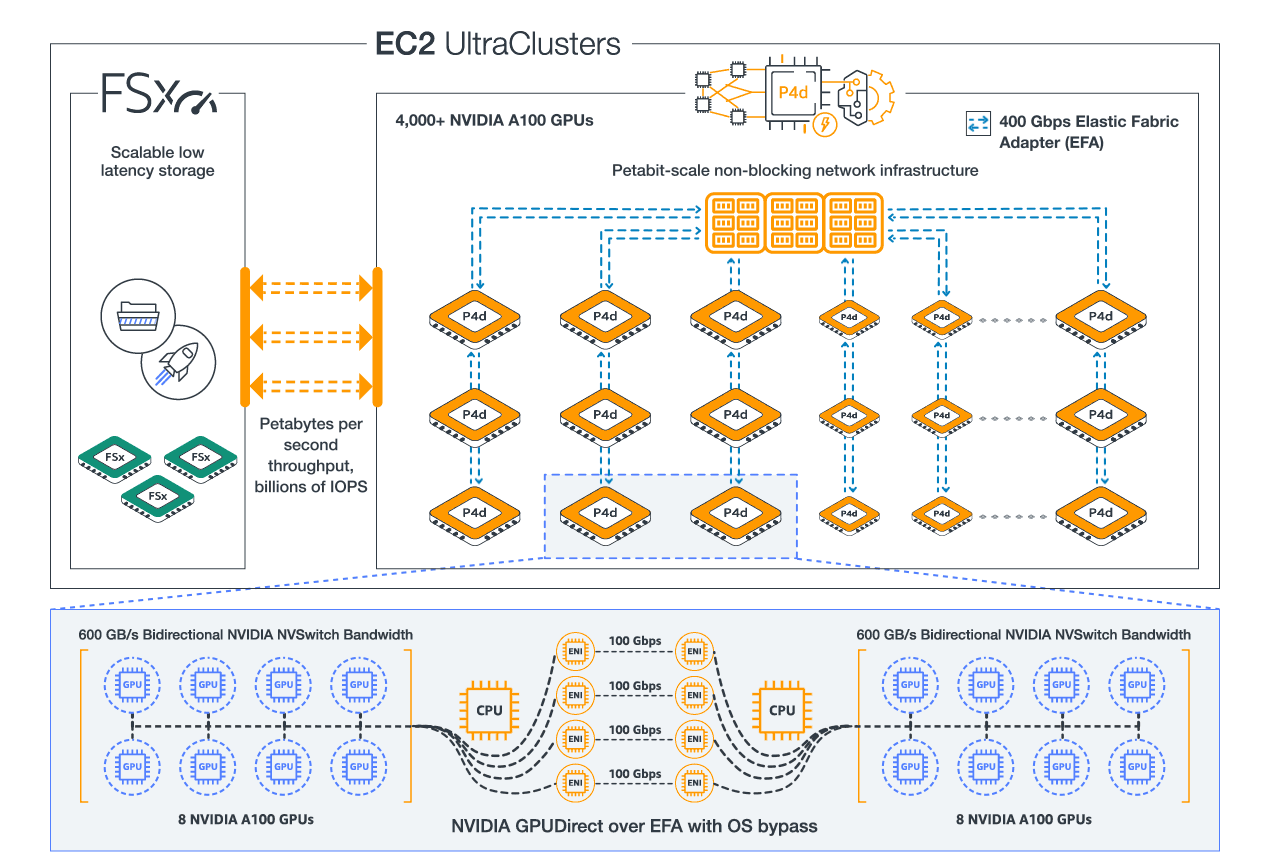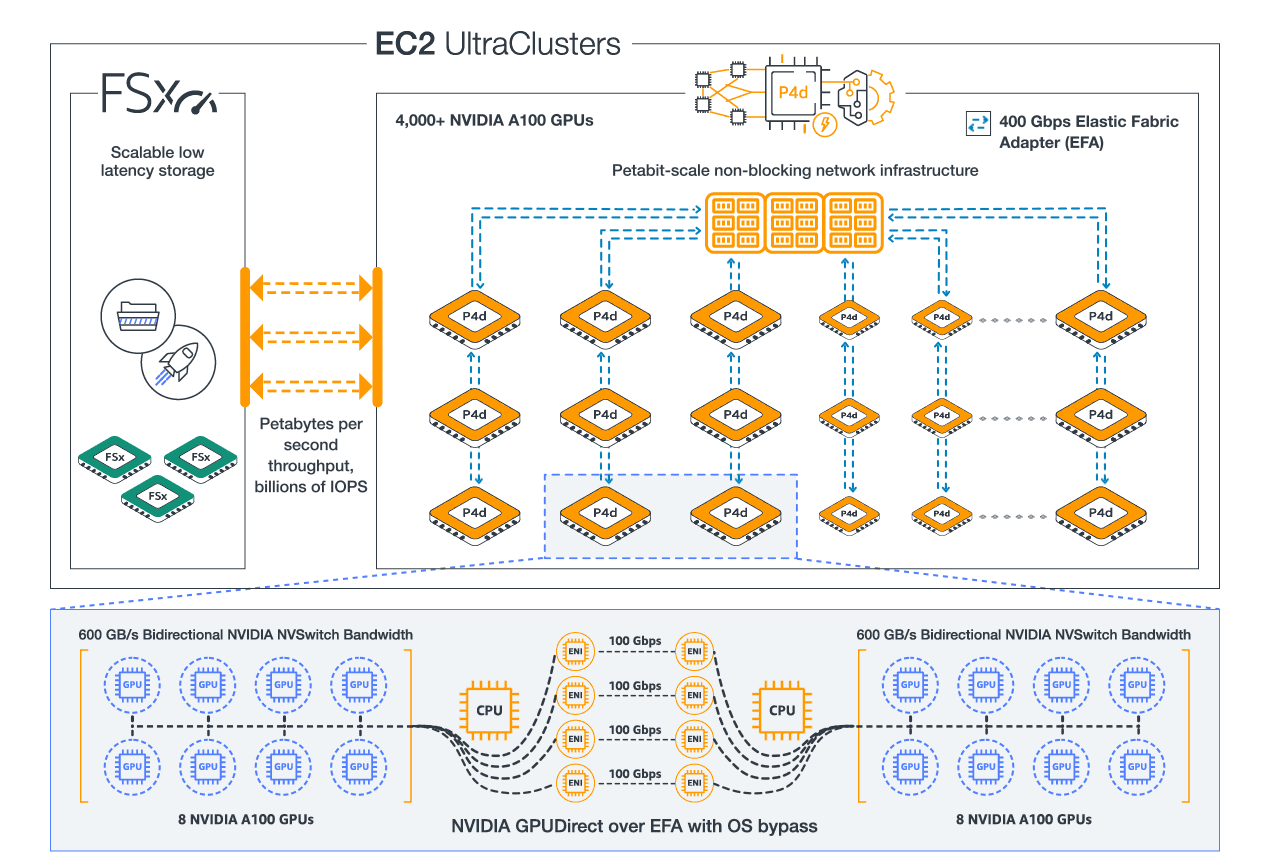
Amazon Web Services (AWS) provides the most elastic and scalable cloud infrastructure to run your Machine Learning. With virtually unlimited capacity, engineers, researchers, HPC system adminsitrators, and organizations can innovate beyond the limitations of on-premises capacity.
ML on AWS removes the long wait times and lost productivity often associated with on-premises training. Flexible ML configurations and virtually unlimited scalability allows you to grow and shrink your infrastructure as your training dictates, not the other way around. Additionally, with access to a broad portfolio of cloud-based services for Storage, Inference and ML Ops, you can reinvent traditional training to train faster and with greater agility.
Find our Machine Learning customer case studies at https://aws.amazon.com/machine-learning/.